七、文件及查找
- 文件
文件是命名的同类客体的记录值的集合。同类客体是指具有相同属性定义的客体。
- 文件的查找
根据用户的要求在文件中确定相应记录的操作过程称为查找,也称检索
平均查找长度(ASL)
计算公式:$$ ASL = \sum_{i=1}^n p_ic_i $$
其中,
n 为存储结构中的对象总数;
$p_i$ 为查找第 i 个记录的概率(在多次查找中,找第 i 个记录的次数占总次数的比例);
$c_i$ 为查找第 i 个记录时所进行过的关键字值比较次数,它取决于被查找记录在文件中的位置
对于具有 n 个记录的文件,若查找每个记录的概率相等,都等于 1/n
$$ASL=\cfrac1n \sum_{i=1}^n c_i$$
顺序文件
文件所包含的记录在物理结构中的排列顺序和在逻辑结构中的排列顺序一致
顺序查找(假设每个记录的查找概率相等:$p_i=\frac 1 n$,比较次数 $c_i=i$)
$$ASL_{SS}=\sum_{i=1}^np_ic_i=\cfrac 1 n \sum_{i=1}^n i = \cfrac{n+1}2$$
若查找失败,则比较的次数为 n,时间复杂度:$O(n)$
折半查找
核心代码:
1 | int bin_search(const int *num, int n, int target) { |
“判定树” 的构造:
把当前查找范围内位置居中的记录的位置(下标)$mid=\lfloor(start+end)/2\rfloor$ 作为二叉树的根节点
前半部分与后半部分的记录的下标分别构成左子树和右子树。
判定树不一定都是二叉树,但是折半查找对应的判定树一定是二叉树
例如:长度 n = 5 的有序文件对应的 ”判定树“ 为:
graph TD
2((2)) --> 0((0))
2((2)) --> 4((4))
0((0)) --> 1((1))
4((4)) --> 3((3))
4((4)) --> 5((5))
判定树不一定都是二叉树,但是折半查找对应的判定树一定是二叉树
查找一个记录的过程对应一条从根节点到该记录对应节点的路径,与关键字值比较的次数正好是该节点在判定树中所处的层数
将判定树近似的看成一棵满二叉树,最大节点数 $n=2^h-1$,则深度 $h=log_2(n+1)$。二叉树中第 j 层的节点数为 $2^{j-1}$,若假定每个元素的查找概率相等,即 $p_i=1/n$,则折半查找的平均查找长度为:
$$ASL_{SS}=\sum_{i=1}^n p_ic_i=\cfrac1n \sum_{i=1}^h j×2^{j-1}=\cfrac{n+1}n log_2(n+1)-1$$
当 n 较大时,$ASL=log_2(n+1)-1$
B- 树和B+ 树
B- 树
B- 树是一种多级索引结构,是一种平衡的多路查找树。
定义:一个 m 阶 B- 树应为满足下列条件的结构:
每个分支节点最多有 m 棵子树
除根节点以外,其他每个分支节点至少有 $\lceil m/2 \rceil$ 棵子树
根节点至少有两棵子树(除非根节点为叶节点,此时 B- 树只有一个节点)
所有叶节点都在同一层上,叶节点不包含任何关键字信息(可以把叶节点看成实际上不存在的外部节点,指向这些 “叶节点” 的指针为空)
所有分支节点中包含下列信息:
$n, p_0, key_1, p_1, key_2, p_2, …, key_n, p_n$
每个节点中还包含了 n 个指向相应记录的指针
其中,n 为该节点中关键字值的个数;
$key_i(1\le i \le n)$ 为该节点的第 i 个关键字值,并且满足关系 $key_i<key_{i+1}(i=1,2…,n-1)$;
$p_i(0\le i\le n)$为指向该节点第 i+1 棵子树根节点的指针。$p_i$ 所指的子树中,所有节点的关键字值均小于 $key_{i+1}$ 而大于 $key_i$
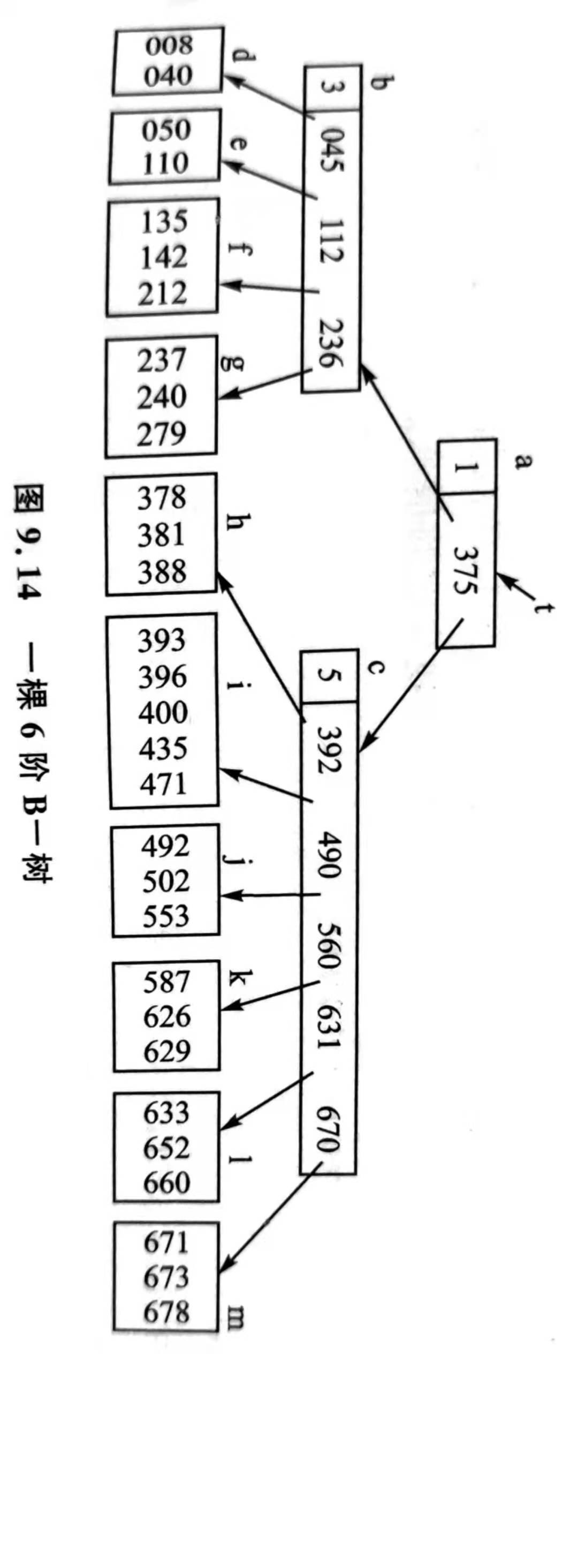
B+ 树
B+ 树是 B- 树的一种变形。在 B- 树中,关键字分布在整个 B- 树上,并且在上一层节点出现过的关键字不再出现在最底层的节点中,而 B+ 树则不是这样
定义:一个 m 阶 B+ 树应为满足下列条件的结构:
每个分支节点最多有 m 棵子树
除根节点以外,其他每个分支节点至少有 $\lceil m/2 \rceil$ 棵子树
根节点至少有两棵子树
有 n 棵子树的节点中有 n 个关键字
叶节点中存放了记录的关键字值以及指向该记录的指针,或者存放基本文件分块之后每一块的最大关键字值和指向该块的指针。叶节点按关键字值大小顺序链接为一个链表。可以把每个叶节点看成是一个基本的索引块(它的指针不再指向另一级索引块,而是直接指向基本文件中的记录)
所有分支节点可看成是索引的索引,节点中仅包含它的各个子结点(下级索引的索引块)中最大(或最小)关键字值及指向子节点的指针
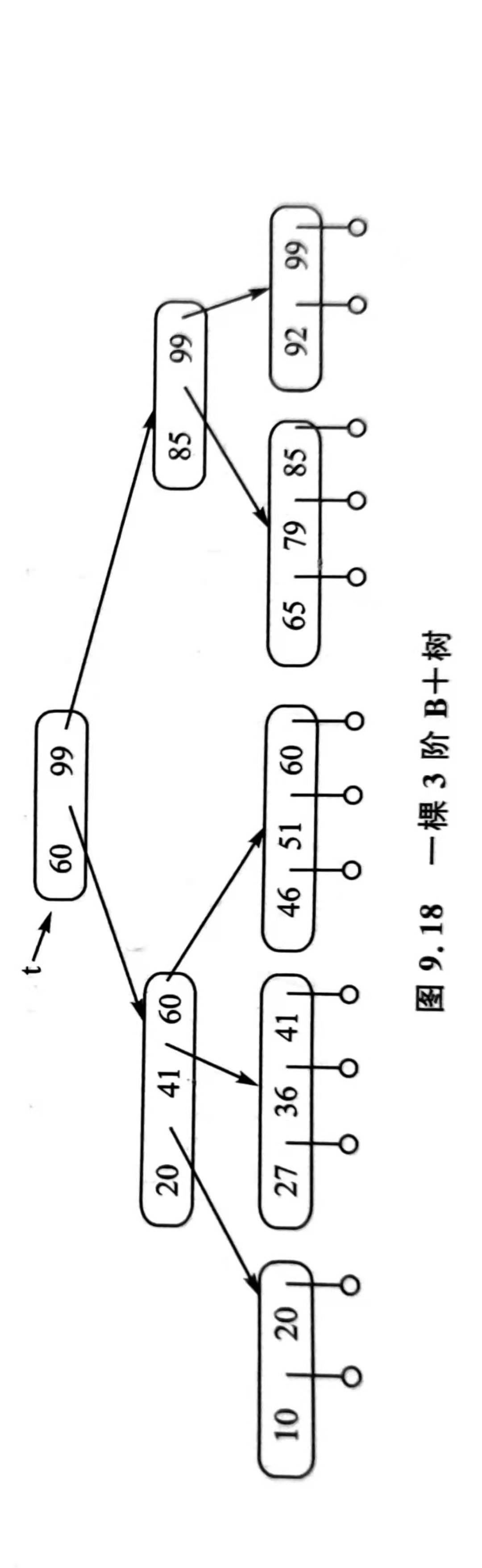
从结构上,B- 树与 B+ 树的区别
从结构上说,B- 树与 B+ 树的主要区别在于:
- 只有 B- 树的每个分支节点给出了该分支节点包含的关键字值的个数;
- B- 树的每个分支节点除了包含若干关键字值外,还包含指向这些关键字值对应记录的指针,而 B+ 树只有叶节点包含了指向关键字值对应记录的指针
- B- 树只有一个指向根节点的入口指针,而 B+ 树有两个入口指针,其中一个指向根节点,另一个指向最左边的叶节点,即指向关键字值最小的那个叶节点(所有叶节点被链接一个线性链表)

